Whole plasmid sequencing

Get the whole picture with fast results and detailed reports. Submit purified DNA, or skip the minipreps with our PrepLESS Flow.
Data and deliverables
- Consensus sequence (.fasta, .gbk)
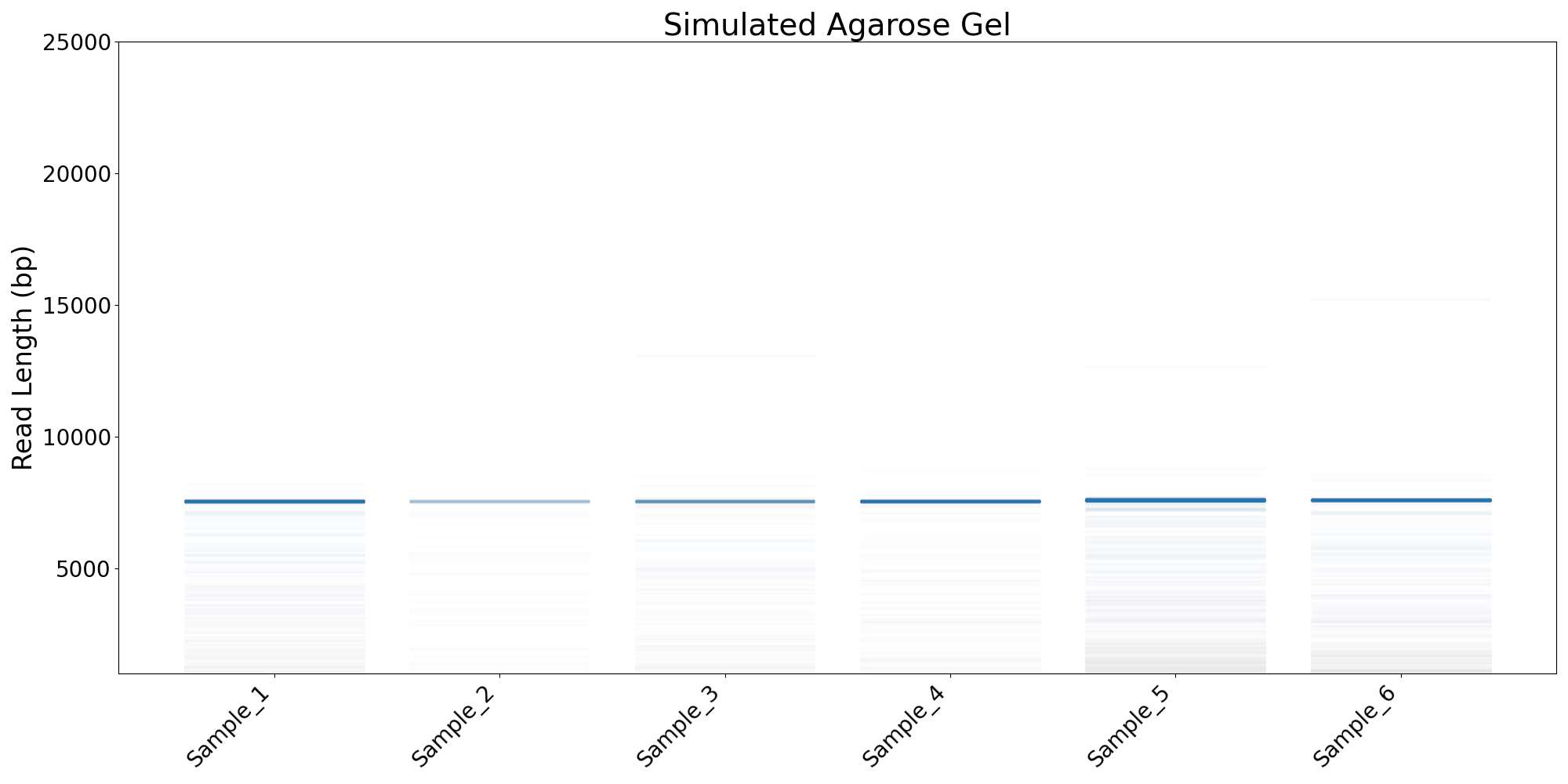
- Simulated agarose gel (.png)
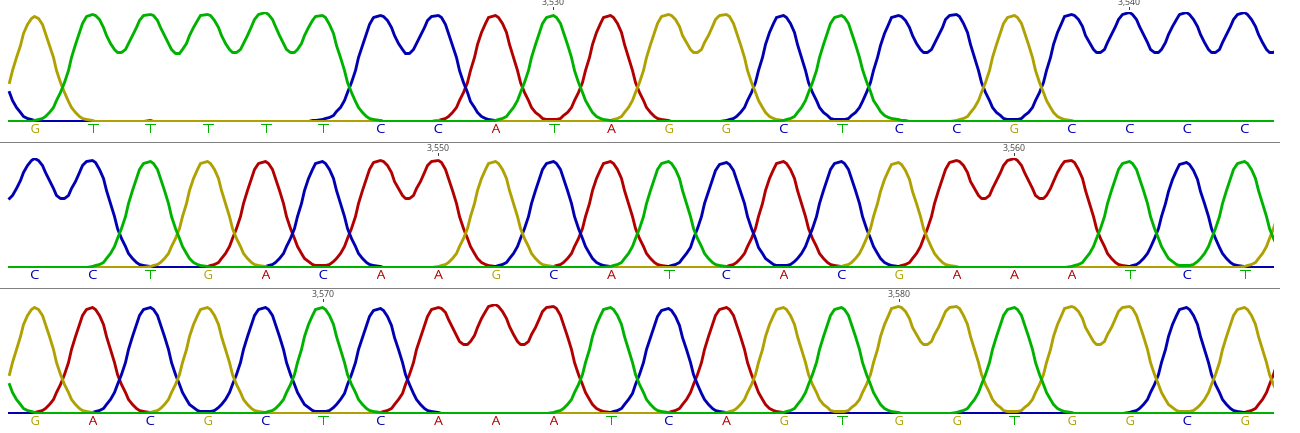
- Chromatogram (.ab1)
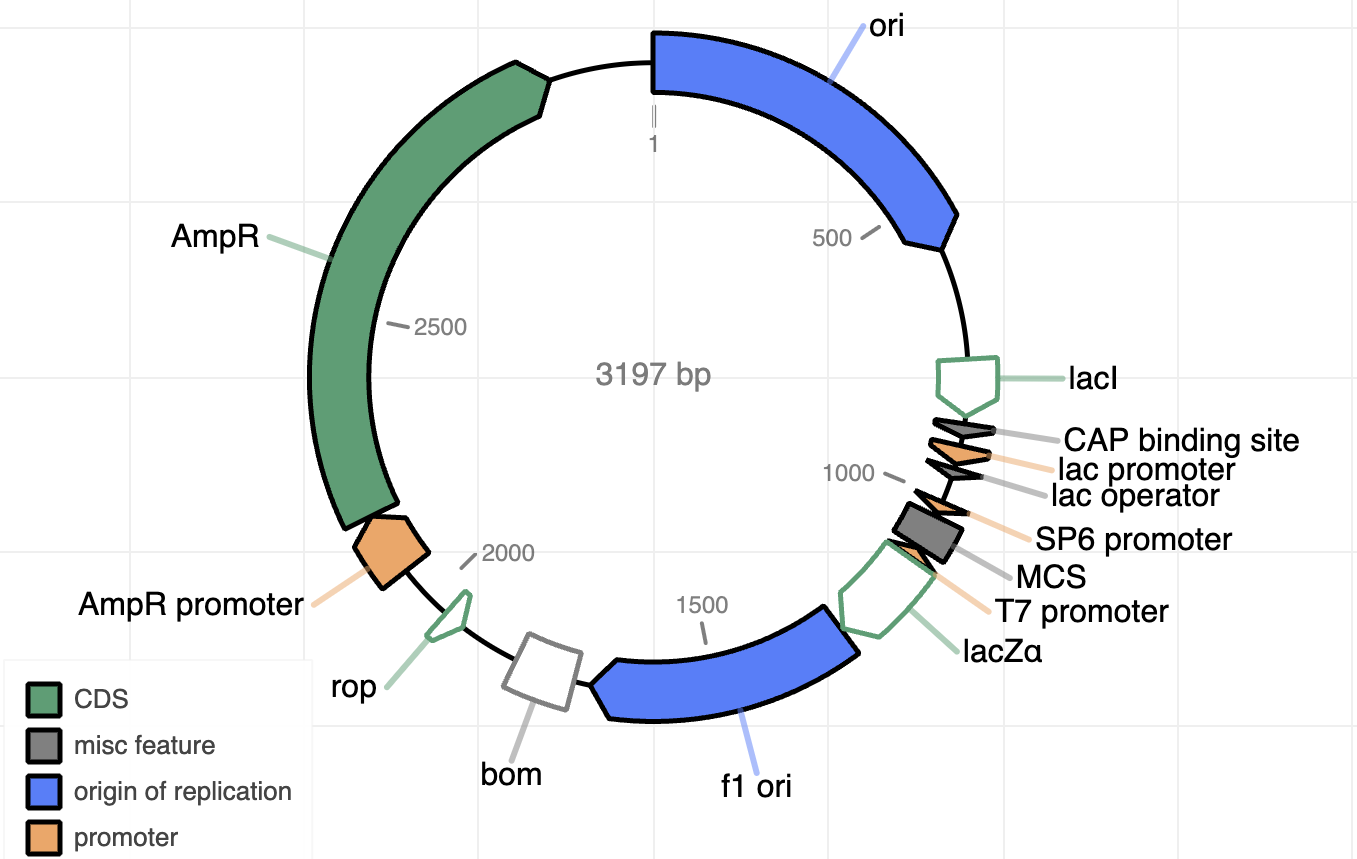
- Annotated map (.html, .gbk)
- Data quality report (.html)
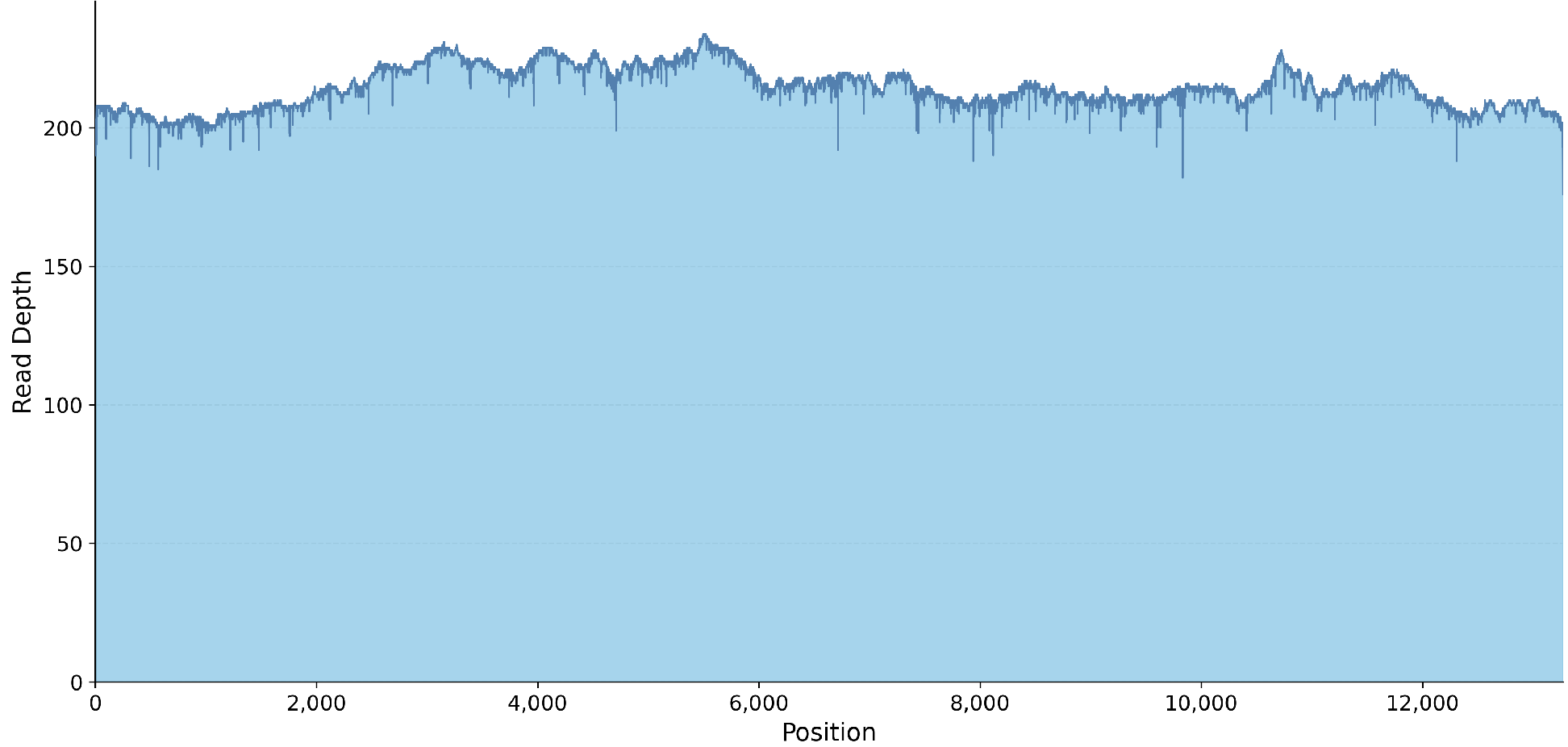
- Coverage plot (.png)
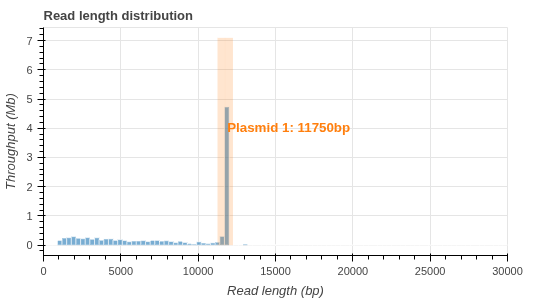
- Read length histogram (.png)
- Raw sequencing reads (.fastq)
- Per-base sequencing information (.txt)
- Responsive customer support

Pricing
All prices shown are Canadian dollars and subject to local sales tax.
Purified plasmids
PrepLESS Flow
Claim back your time- we'll extract your plasmids for you. Pricing includes standard plasmid sequencing and analysis.
Frequently Asked Questions
What is your PrepLESS Flow?
PrepLESS Flow lets you skip the miniprep entirely. Submit colonies circled on an agar plate, resuspended colonies in water, or 100 µL of liquid culture, and we’ll handle plasmid extraction and sequencing in one workflow. It’s $30 per sample and delivers in 1 business day — ideal for cloning workflows where the miniprep step is the bottleneck.
What plasmid sizes can you sequence?
From small plasmids (~1 kb) up to 300 kb constructs. The size of your plasmid determines which service tier to choose: Standard for <25 kb, Large for 25–125 kb, and Extra-large for 125–300 kb. See the pricing tables above for concentration and volume requirements at each tier.
How should I prepare my plasmid?
Submit column-purified or bead-purified plasmid DNA at the concentration listed for your service tier. Avoid linearization unless you specifically want linear-read coverage — our default workflow produces full-length reads from supercoiled or relaxed circular input. For PrepLESS Flow, just send colonies or culture and we will handle the rest.
What files will I receive?
By default, you will receive a single consensus sequence (.fasta), simulated agarose gel (.png), chromatogram (.ab1), annotated plasmid map (.gbk, .html), data quality report (.html), coverage plot (.png), read length histogram (.png), sequencing reads (.fastq), and per-base sequencing information (.txt). If you would like to request additional files or analyses, please specify in the “Additional Information” section.
When will I receive my data?
Standard plasmid sequencing and PrepLESS Flow complete in 1 business day from receipt of samples, although we typically measure return time in the hours scale. If you need data ASAP, let us know.